Abstract
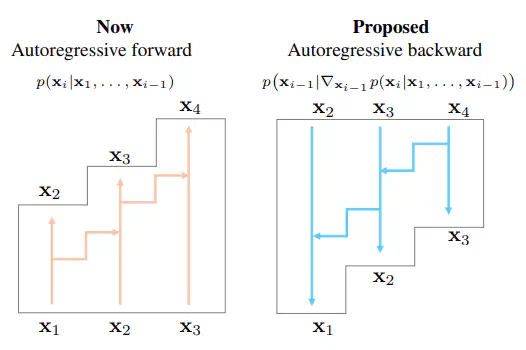
The current landscape of defensive mechanisms for LLMs is fragmented and underdeveloped, unlike prior work on classifiers. To further promote adversarial robustness in LLMs, we propose Inverse Language Modeling (ILM), a unified framework that simultaneously 1) improves the robustness of LLMs to input perturbations, and, at the same time, 2) enables native grounding by inverting model outputs to identify potentially toxic or unsafe input triggers. ILM transforms LLMs from static generators into analyzable and robust systems, potentially helping RED teaming. ILM can lay the foundation for next-generation LLMs that are not only robust and grounded but also fundamentally more controllable and trustworthy.
Davide Gabrielli
Collaborator & PhD Student
My research interests include Adversarial Attacks on LLMs and Explainable AI.
Simone Sestito
Sofware Engineer at Bending Spoons
My research interests include Adversarial Attacks on LLMs.