Abstract
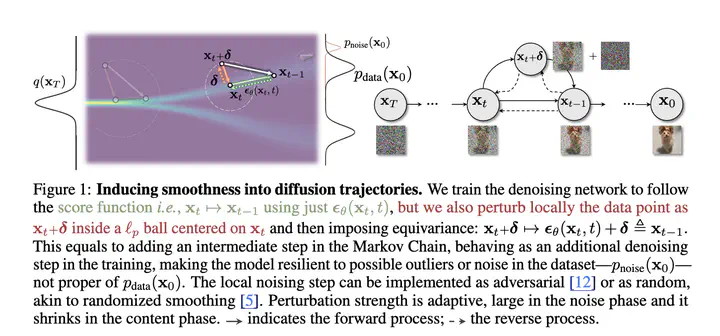
We answer the question in the title showing that adversarial training (AT) for diffusion models (DMs) fundamentally differs from classifiers: while AT in classifiers enforces output invariance, AT in DMs requires equivariance to keep the diffusion process aligned with the data distribution. We define AT as a way to enforce smoothness in the diffusion flow, improving robustness to outliers and corrupted data. Unlike prior art, our method makes no assumptions on the noise model and integrates seamlessly into diffusion training by adding either random noise–similar to randomized smoothing–or adversarial noise–akin to AT. This enables intrinsic capabilities such as handling noisy data, dealing with extreme variability such as outliers, preventing memorization, and obviously improving robustness. We rigorously evaluate our approach with proof-of-concept datasets with known distributions in low- and high-dimensional space, thereby taking a perfect measure of errors; we further evaluate on standard benchmarks such as CIFAR-10, CelebA and LSUN Bedroom, showing strong performance under severe noise, data corruption and iterative adversarial attacks. Code is available at https://github.com/OmnAI-Lab/Adversarial-Training-DM.git
Maria Rosaria Briglia
PhD Student
Hello everyone! My name is Maria Rosaria, a Ph.D. student in AI Security, based in Sapienza University. My main research interest is in developing adversarial techniques in the generative AI domain, with a particular focus on Diffusion Model’s technology, and applying them also to the world of Explainable AI. My main research topics are Diffusion Models, Adversarial Machine Learning and Explainble AI by counterfactual examples.
Mirza Mujtaba Hussain
PhD Student
Hi there! 👋 I’m Hussain, a Ph.D. student at Sapienza University. Currently I’m diving into Adversarial Machine Learning and Explainable AI to find practical solutions for real-world challenges. My goal is to use AI to make a positive impact on our society.